In 2025, the gap between organizations that can act on data and those that are still wrestling with pipelines has never been wider. The enterprises pulling ahead aren't necessarily those with the most data — they're the ones who've built architectures that turn raw information into reliable, real-time decisions.
This article walks through what that architecture looks like in practice: the layers, the patterns, and the design decisions that determine whether your AI investments generate real ROI or remain perpetually "almost production-ready."
The Foundation: Why Architecture Matters More Than Models
A common misconception is that AI success is primarily a model problem. In reality, 80% of the work — and most of the failure points — live in the data infrastructure beneath the model. A highly accurate model fed stale, incomplete, or inconsistently formatted data produces unreliable outputs. Garbage in, garbage out is not just a cliché; it's an architectural requirement.
An AI-ready architecture solves three core problems:
- Data freshness — How quickly does new information propagate to decision systems?
- Data trust — How confident are you that the data is complete, accurate, and consistent?
- Decision latency — How fast can the system move from observation to action?
The Modern Data Architecture Stack
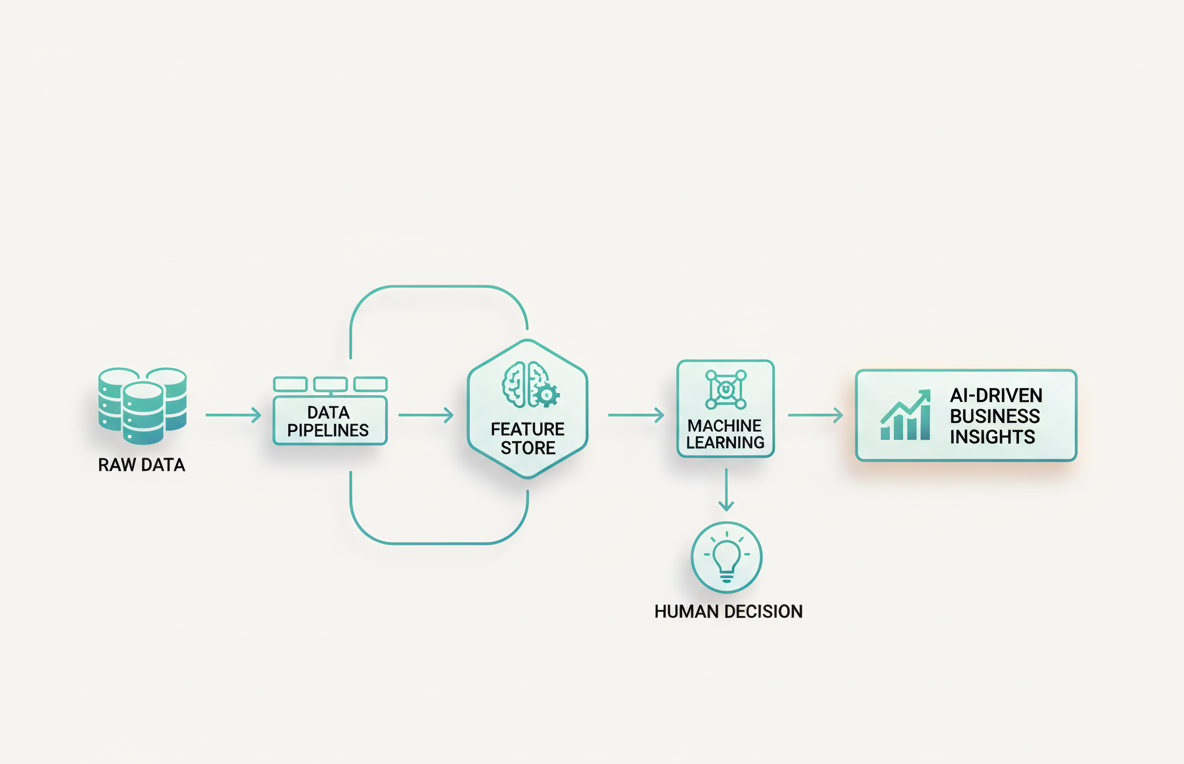
1. Ingestion Layer
The ingestion layer is where raw data enters your system. For AI-ready architectures, this typically means supporting both batch and streaming ingestion simultaneously. Tools like Apache Kafka, AWS Kinesis, or Pub/Sub handle high-throughput event streams, while orchestration tools like Airflow or Prefect manage scheduled batch loads from databases, APIs, and file systems.
Design principle: Treat every data source as unreliable. Build for idempotency, schema evolution, and failure recovery from day one — not as an afterthought.
2. Storage and Transformation Layer
Modern data warehouses like Snowflake, BigQuery, and Databricks provide the analytical foundation. But the transformation layer — where raw data becomes curated, business-ready datasets — is where architectures most commonly break down.
dbt (data build tool) has emerged as the standard for this layer, enabling version-controlled, testable SQL transformations that treat data assets as software. Combined with a medallion architecture (bronze → silver → gold), you create a clear lineage from raw ingestion to AI-ready features.
3. Feature Store
A feature store bridges the gap between data engineering and machine learning. It provides a centralized repository of pre-computed features that can be served both for training (historical) and inference (real-time). Without this layer, teams duplicate feature computation across projects, creating inconsistencies between training and serving environments — one of the most common causes of model degradation in production.
4. AI/ML Layer
This is where models are trained, evaluated, and deployed. MLflow, Weights & Biases, and SageMaker provide experiment tracking and model registry capabilities. The key architectural decision here is the serving pattern: batch inference for non-latency-sensitive workloads, online inference for real-time decisions.
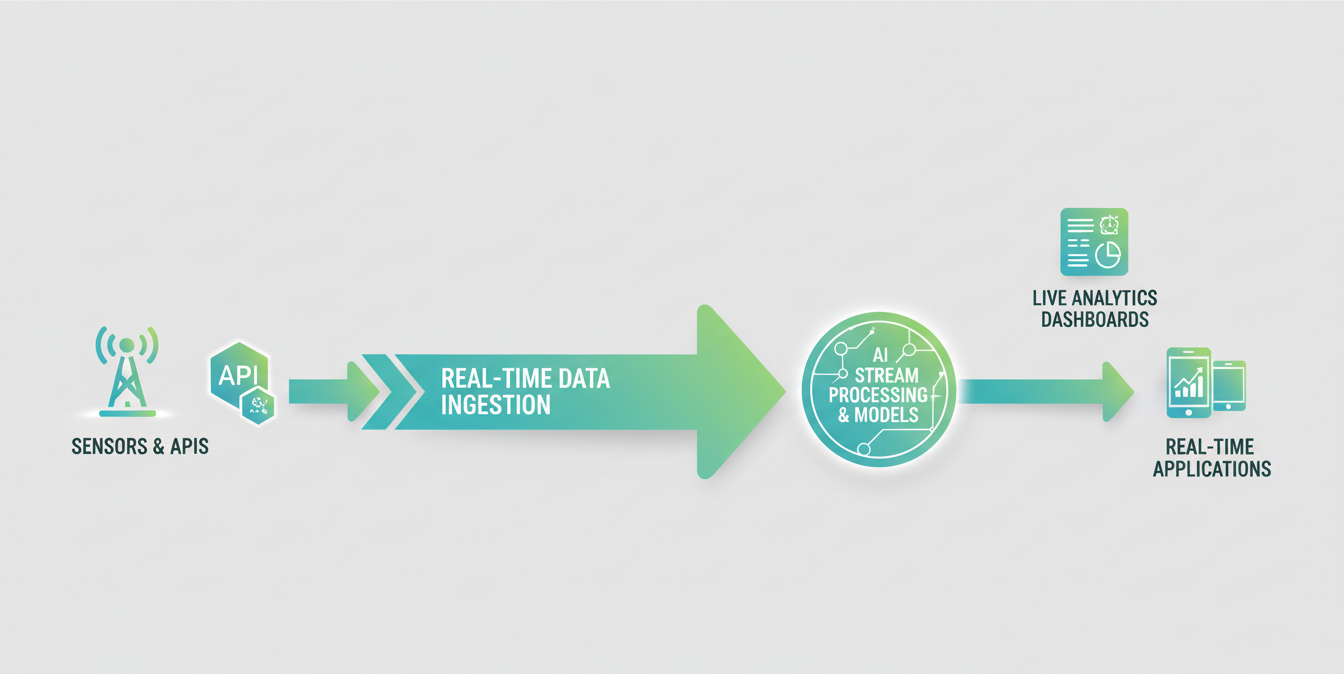
Intelligent Pipelines: The Connective Tissue
Pipelines are the nervous system of an AI architecture. A well-designed pipeline is:
- Observable — Every stage emits metrics, logs, and traces
- Testable — Data quality checks run at every transformation boundary
- Recoverable — Failures trigger clear alerts and can be restarted without data loss
- Documented — Data lineage is tracked automatically
The Xcdify Blueprint for AI-Ready Data
At Xcdify, our approach to AI-ready data architecture follows a few core principles:
- Start with the decision, not the data. What decisions does this architecture need to support? Work backwards to define the data requirements.
- Automate data quality. Every dataset has a contract. Violations trigger immediate alerts before they reach models.
- Build for drift. Models degrade as the world changes. Monitoring data distribution and model performance in production is non-optional.
- Invest in the feature store early. It's the highest-leverage investment for teams moving from one model to many.
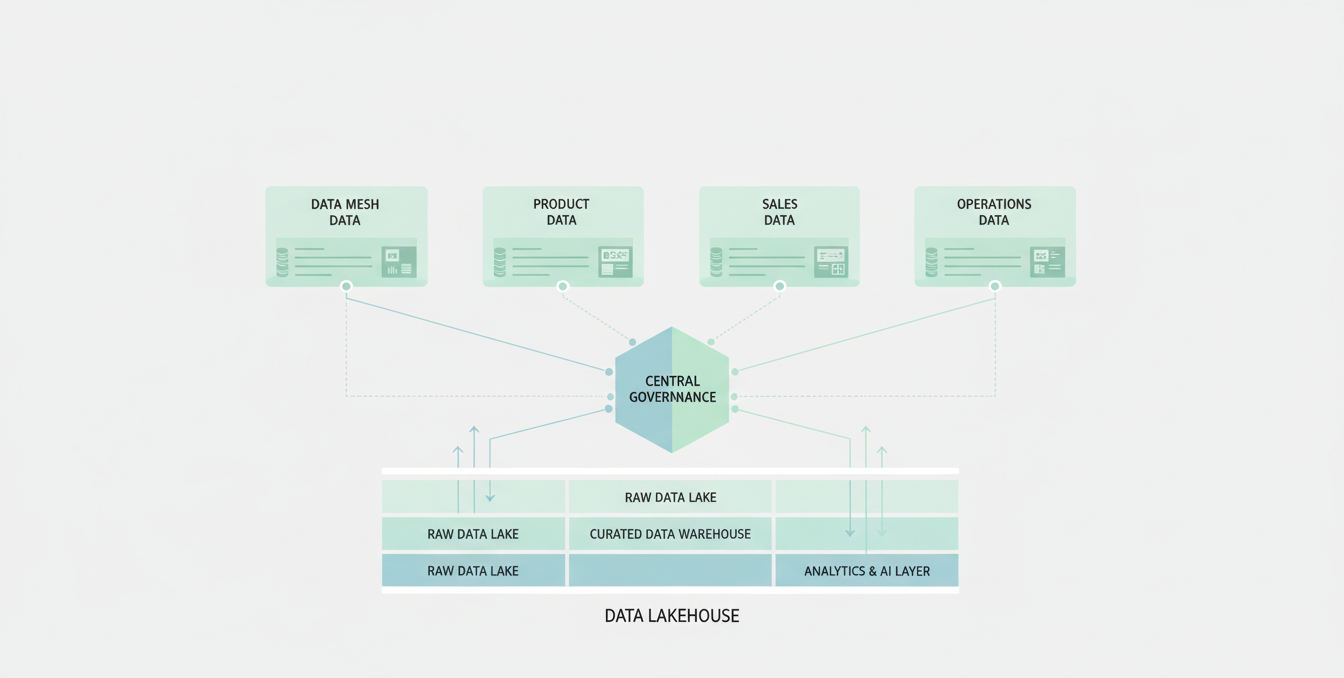
Trust and Governance
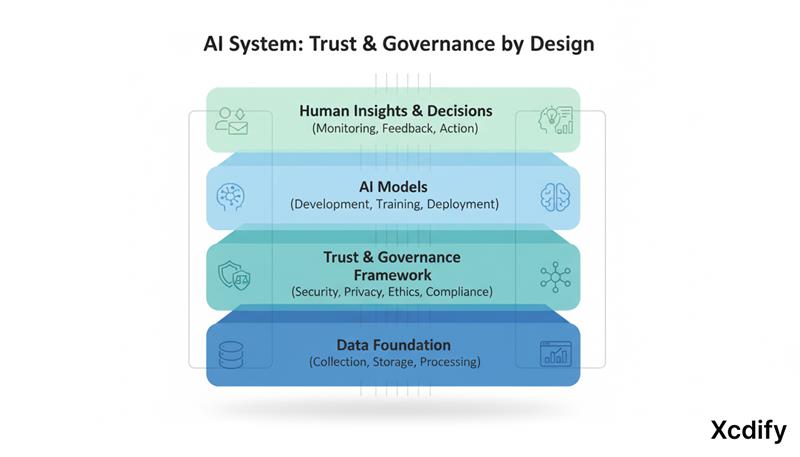
As AI systems make higher-stakes decisions, governance becomes a critical architectural concern. This means:
- Data lineage tracking from source to decision
- Role-based access control for sensitive data
- Model explainability for regulated use cases
- Audit trails for every inference that informs a business decision
These aren't constraints on AI capability — they're what makes it trustworthy enough to deploy in production at scale.
Conclusion
Building an AI-ready architecture isn't a one-time project — it's an ongoing capability. The organizations winning with AI in 2025 are those that have made this infrastructure a first-class engineering priority, not an afterthought to model development.
If you're looking to assess your current data architecture or build the foundation for AI at scale, reach out to the Xcdify team. We've helped enterprises across healthcare, fintech, and manufacturing turn their data from a liability into a competitive advantage.